手書き・印刷さまざまな文書に対して業界最高レベルの読み取り精度を実現 FAX-OCRシステムなどを支える、高度な文字認識技術
公開:2003年03月01日
三菱電機インフォメーションシステムズ(株)が開発・販売しているFAXOCRシステム「MELFOS」は、枠線帳票をFAX受信し、記入されている手書き文字を自動認識した後、テキストデータに変換して他のアプリケーションに出力するシステムです。
既存のファクシミリをデータ入力端末として使い、効率的な受発注システムなどを構築できるとあって、製造業・流通業を始め、多くの企業から引き合いをいただいています。MELFOSの特長は、業界最高レベルを誇る手書き文字認識率や、FAX特有の画像のカスレや伸縮にも対応できること、さらに、黒枠罫線の帳票だけでなく、さまざまなデザインの帳票に対応できることなどが挙げられます。
そこで今回は先端技術レポートとして、情報技術総合研究所(以下、情報総研と略)の音声・言語処理技術部を訪ね、MELFOSをはじめとする文書読み取り応用機器のキーテクノロジーである三菱電機の高度な文字認識技術について取材しました。
応用範囲の広がる文字認識技術
文字認識技術は、FAX-OCRシステム以外にも、さまざまなシステムに欠かせない技術となっています。たとえば、ペン入力方式のモバイルコンピュータでは、タブレット上のペンの動きを認識して文字を入力することが可能です。また、文字を書くときの個人のクセを識別して、サイン(署名)照合にも応用することができます。
FAX-OCRシステムの発展形として、FAX送信された文書の内容を自動認識し、必要な情報を抽出してHTML変換し、ホームページに自動掲載するシステムも考えられます。またカメラで撮像した文字の認識では、コンテナ番号などを自動認識するシステムがすでに実用化されています。
「自由なフォーマットで自由に記載された文字を確実に読み取る技術を、常に追求しています」と、音声・言語処理技術部 岡田康裕 チームリーダーは話します。MELFOSにも使われている文字認識技術は、今日も進化を続けているのです。

岡田 康裕 チームリーダー

平野 敬 主事
FAX-OCRシステムの信頼性を支える帳票解析技術
文字認識技術には、手書き文書読み取り、印刷文書読み取り、画像中の文字読み取りなどの用途に応じて、さまざまな技術領域があります。三菱電機は、FAX-OCRシステムに適用する手書き文書読み取り技術として、英字・数字・カタカナ・記号を読み取る方式と漢字を読み取る方式の2つの方式を開発しています。さらに、2つの方法による文字認識に加えて、ノイズ除去、フィールド抽出などの帳票解析技術を組み合わせることで業界最高性能のFAX-OCRシステムを実現しています。たとえば、発注書用紙に必要な項目を手書きで記入し、MELFOSで処理する場合を例に考えてみましょう。
受信したFAX画像は、部分的に背景が黒くなっていたり、縦線が入っていたりと、FAX特有の「ノイズ」が入ることがよくあります。MELFOSは、このような画像でも4種類のFAX特有のノイズを検知し、文字部分に影響を与えることなく、ノイズを除去することができます(図1参照)。
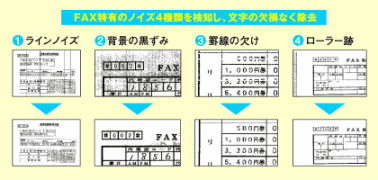
「他社製品では、読み取りエラーになって受け付けないようなノイズの多いFAX画像でもクリアな画像にすることができるのは、当研究所で開発した高度なノイズ除去技術が活かされているからです」と、音声・言語処理技術部 平野敬 主事は説明します。
ノイズを除去した後、読み取るべき文字が書いてある場所(フィールド)を特定します。ここで用いられる「フィールド抽出」と呼ばれる技術でも、情報総研は独自の手法を開発、FAXによって斜めに変形したり、フィールドを囲む四角形の一部が欠けたりした帳票画像でも、変形量を推定し、適切なフィールドを抽出することを可能にしました。さらに、これまでは読み取りが困難であった多様な形式の帳票にも、柔軟に対応することができるようになりました(図2参照)。

業界最高精度を誇る手書き文書読み取り技術
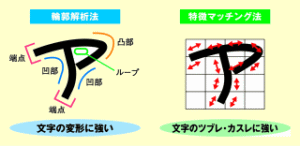
抽出フィールド内の英字・数字・カタカナ・記号に対する文字認識については、輪郭解析法と特徴マッチング法を併用します。輪郭解析法は、端点、凸部、凹部などの形状の構造を捉える方法です。文字が斜めになっているなどの変形には強い認識技術ですが、一部欠損やツブレなどによって認識ミスが起きる場合があります。これに対して特徴マッチング法は、文字領域をメッシュに分割し、メッシュ内の線が水平方向に伸びているか右斜め下方に伸びているかなどの特徴を捉えます。輪郭解析法とちょうど逆で、文字の一部欠損やつぶれなどに対応できる方法ですが、文字の変形に対応するためには工夫が必要です。情報総研は、この両方の認識方法を併用したハイブリッド技術によって、手書き文字の認識率を高めています(図3参照)。
手書き漢字認識については、外郭ゼロ交差特徴と正準判別分析を採用しています。外郭ゼロ交差特徴とは、2値画像を、全体をぼかした多値画像としてパターン処理したうえで、文字と背景の境界部分の特徴を捉えて認識する方法です(図4参照)。
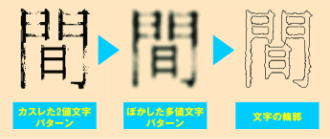
白か黒かという2値画像では、かすれた文字やつぶれた文字を認識できませんが、多値画像にいったん変換することで、精度の高い文字認識が実現できます。また、正準判別分析では、文字の特徴を表す数値を似た文字同士が区別しやすいように辞書を作成することで、変形した文字も高い精度で認識できます。この方式により、独立行政法人産業技術総合研究所(旧電子技術総合研究所)が提供している手書き漢字データベースETL9B(日本語の文字認識率ベンチマークとして有名な、独立行政法人 産業技術総合研究所(旧 電総研)が提供する公開データベース)を用いたテストにおいて、業界最高レベルの98%以上の認識率を実現しました。
印刷文書読み取り技術、検索技術にも独自の境地
手書き文書読み取り技術のほかにも、情報総研音声・言語処理技術部が誇る技術はたくさんあります。たとえばPDMMASTAR、FINALFILING、PerfectFilingなどの文書管理システムでは、印刷文書読み取り技術が活用されています。印刷文書の読み取りでは、手書き漢字認識と同様に外郭ゼロ交差特徴と正準判別分析を採用しています。さらに、文書に記載された文字列の認識精度を改善する手法として、n-gram言語モデルを適用しています。n-gram言語モデルは、特定の文字の後にどのような文字が出現しやすいかという確率を元にして日本文らしさを算出する方法です。たとえば、横倍角で記入された「競走」という文字列に対して「克克走」という3文字の文字列として認識された場合でも、区切り方を変えて文字並びの確率を計算することで「競走」という2文字の方がより日本文らしいと判定され、最終結果として正しい結果が出力されます。
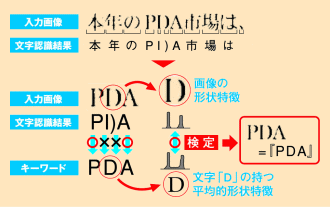
また、一旦蓄積した文書に対してキーワードで全文検索する場合には、形状特徴併用検索技術を用います。文書ファイリングシステムでは、人手をかけて文字を正確にコード化することよりも、手軽に文書が登録でき自由に閲覧・検索できることが重要です。そこで情報総研では、形状特徴併用検索技術を独自に開発しました。形状特徴併用検索技術では、文字の形状を表現した特徴に基づいて検索対象文字列と検索キーワードとを照合します。これにより、文書内の文字を認識する段階で誤って認識した文字でも、文書検索の際に正確に検索することができます。たとえば「D」という文字が誤って「1)」と登録されていても、「PDA」というキーワードで検索すると、「D」の形と「1)」の元となった文字列画像の形を比較して「P1)A」という文字を含んだ文書も正確に検索できます(図5参照)。
さまざまな技術の精度を上げ、それらを組み合わせることで進化する文字認識技術。「文字認識技術はまだまだ奥が深く、応用範囲もどんどん広がります。人間は、2000文字に1文字しか間違えません。コンピュータの世界でも、『人間並み』を追及していきたいですね」と岡田チームリーダーは抱負をにこやかに語ってくれました。
記事について
「エキスパート・インタビュー」の最新記事



メールマガジン登録
上記コラムのようなお役立ち情報を定期的に
メルマガで配信しています。
コラム(メルマガ)の
定期購読をご希望の方はこちら

